Collecting and Using Metrics¶
A metric is any value you can measure over time. It can be blocks used on a filesystem, the number of nodes in a cluster, or a temperature reading. Observe ingests this time series data into event datasets. Any event dataset with a numerical value column can be interpreted as a metric dataset in Observe, in Metrics Explorer, a dashboard, a worksheet, or a monitor. Each point in a time series represents a measurement from a single resource, with its name, value, and tags.
A metric has three major metadata attributes:
Metric Type: The metric type is used by Observe to interpret the reported values. It is critical to set the Metric Type correctly. For instance, a
cumulativeCounter’s normal reset could look like a service failure if that metric is mistakenly typed as agaugeordelta.Measurement Type: The metric’s measurement type describes the data type reported in each point. Observe supports
float64andtdigestas data type.Unit: The metrics’ unit describes the unit of the measurements, such as
kBorkB/s. Observe uses these attributes to display metrics properly in charts.
Types of Metrics Collected by Observe¶
Metric type is used to drive default visualization behaviors in metric expression builders (such as Metrics Explorer or a Threshold Metrics Monitor. The metric type also affects the behavior of alignment function that are sensitive to metric types, such as rate and delta.
Note
The Metric type drives default visualization behavior. If the default is not the desired behavior, you can easily switch the alignment functions in the expression builder: for instance, change avg() to rate() or change rate() to delta().
You can view the type of an ingested metrics dataset by hovering over the name in Metrics Explorer. It is useful to confirm that the type is set correctly, as false positive or negative results could occur from incorrectly typed metrics.
Observe supports the following Metrics Types:
The gauge metric type represents a snapshot of the state at the time of collection. Use a gauge metric type to measure data that is reported continuously, such as available disk space or memory used. The value of a gauge metric can go up or down or stay the same.
Given a series of memory measurements, such as pod_memory_working_set_bytes from Kubernetes, an example data series might look like 31, 30.5, 31, 31, 31.5.
In a gauge metric of pod_memory_working_set_bytes, all reported values are retained. Query time parameters are then used to calculate and display what the user requires.
The cumulativeCounter metric type represents a cumulative measurement that is measured since the creation of the time-series. The value can only increase (monotonically), or reset to zero when restarted.
Given a series of CPU measurements, such as pod_cpu_usage_seconds_total as used in Kubernetes, the CPU measurements accumulated since the pod started. An example data series might look like 36.33, 36.61, 40.96, 652.20, 1097.59.
In a cumulativeCounter metric of pod_cpu_usage_seconds_total, all of the values are reported (36.33, 36.61, 40.96, 652.20, 1097.59).
The delta metric type represents the value change since the last collected report. For example, if CPU utilization increased from 50% to 80% during a metric reporting interval, the delta metric reported for it would be 30%. The value of a delta metric can go up or down or stay the same.
Given a series of memory measurements, such as pod_memory_working_set_bytes from Kubernetes, an example data series might look like 31, 30.5, 31, 31, 31.5.
In a delta metric of pod_memory_working_set_bytes, the first measurement is reported, followed by the delta at the end of the period (31, 0.5).
The tdigest metric type contains data points that summarize multiple measurements in a single tdigest value. All points in the time series are independent (as for gauge metrics). This metric type is useful to calculate percentiles in a performant way.
Suppose we have a dataset containing Span durations. After filtering the durations of only one Span we are interested in, we could summarize such span’s durations into tdigest values at regular time intervals. Then, we could extract the n-th percentile at each point in the time series, effectively generating a plot of “n-th percentile duration of Span X”.
The metric type can be explicitly set with set_metric. Whenever the metric type is not explicitly set, Observe will attempt to auto-assign a metric type. This is true for all float64 metrics (gauge, cumulativeCounter and delta). Metrics of type tdigest cannot be automatically discovered by Observe. Use set_metric options(type:"tdigest"), "metric-name" to get the correct metric visualization behavior for tdigest metrics.
Metric types do not affect how metric data is collected or stored, but they are used at query time. A metric is tabulated to make a chart or test a monitored condition. This requires a time resolution, which Observe dynamically determines based on your query window size. For instance, a query window of four hours would have a resolution of one minute; while a query window of one day will have a resolution of five minutes.
The chart or table’s behavior is also established by using an OPAL alignment function. This is a mathematical operation used on the values in each time resolution window to determine which value to show in the table or chart. For instance, a metric might have points at every thirty seconds, while our chart has a five minute resolution. This means each five minute window has ten measurements to evaluate. The avg() function will show the average of those ten values.
Metric types affect the run time behavior of some operations that use alignment functions.
delta: calculates the value difference of the argument in each time bin for each group.deltamay produce negative values when the argument decreases over time.for gauge metrics,
deltaretains the default behavior. Negatives may be produced when the value is decreasing.for cumulativeCounter metrics,
deltawill assume the values to be monotonically increasing, and treats decreasing values as counter resets. Negatives will not be produced forcumulativeCountertype metrics.for delta metrics,
deltawill sum up the values in the time window to return the total sum. Negatives may be produced for negative input values.
delta_monotonic: calculates the amount of difference in a column in each time bin for each group.delta_monotonicby default assumes the argument to be monotonically increasing, and treats decreasing values as counter resets.for gauge and cumulativeCounter metrics,
delta_monotonicretains the default behavior of assuming monotonic increases.for delta metrics,
delta_monotonicwill sum up the values in the time window to return the total sum. Negatives may be produced for negative input values.
deriv: calculates the average per-second derivative of the metric during each time framefor gauge metrics,
derivcomputes the value change over the time frame, allowing negative changes, and then divides the value change with time frame size.for cumulativeCounter metrics,
derivcomputes the value change over the time frame, treating value decreases as counter resets to prevent negative changes, and then divides it by the time frame size.for delta metrics,
derivcomputes the value change by summing up the deltas, and then divides it by the time frame size.
rate: calculates the average per-second rate of increase of the metric during each time framefor gauge and cumulativeCounter metrics,
ratecomputes the value increase over the time frame, assuming monotonic increase in the value and treating decreasing values as counter resets, and then divides the value increase by the time frame size.for delta metrics,
ratecomputes the value increase by sums of the deltas, and then divides it by the time frame size.
Understanding Alignment¶
Alignment along the time dimension¶
Metrics are usually very dense (contain lots of measurements at a high frequency). It is often useful to visualize a metric over time at more user friendly intervals. I.e. disk usage metrics might have one value every 1s, and we might want to plot such usage over the Black Friday week. Therefore, the ideal plotting format would be to have disk-usage summaries every 10m. Alignment is a computation that rearranges a time series into regular time intervals, aggregating multiple data points of a time series into one data point for each time interval. A typical alignment operation looks like this:
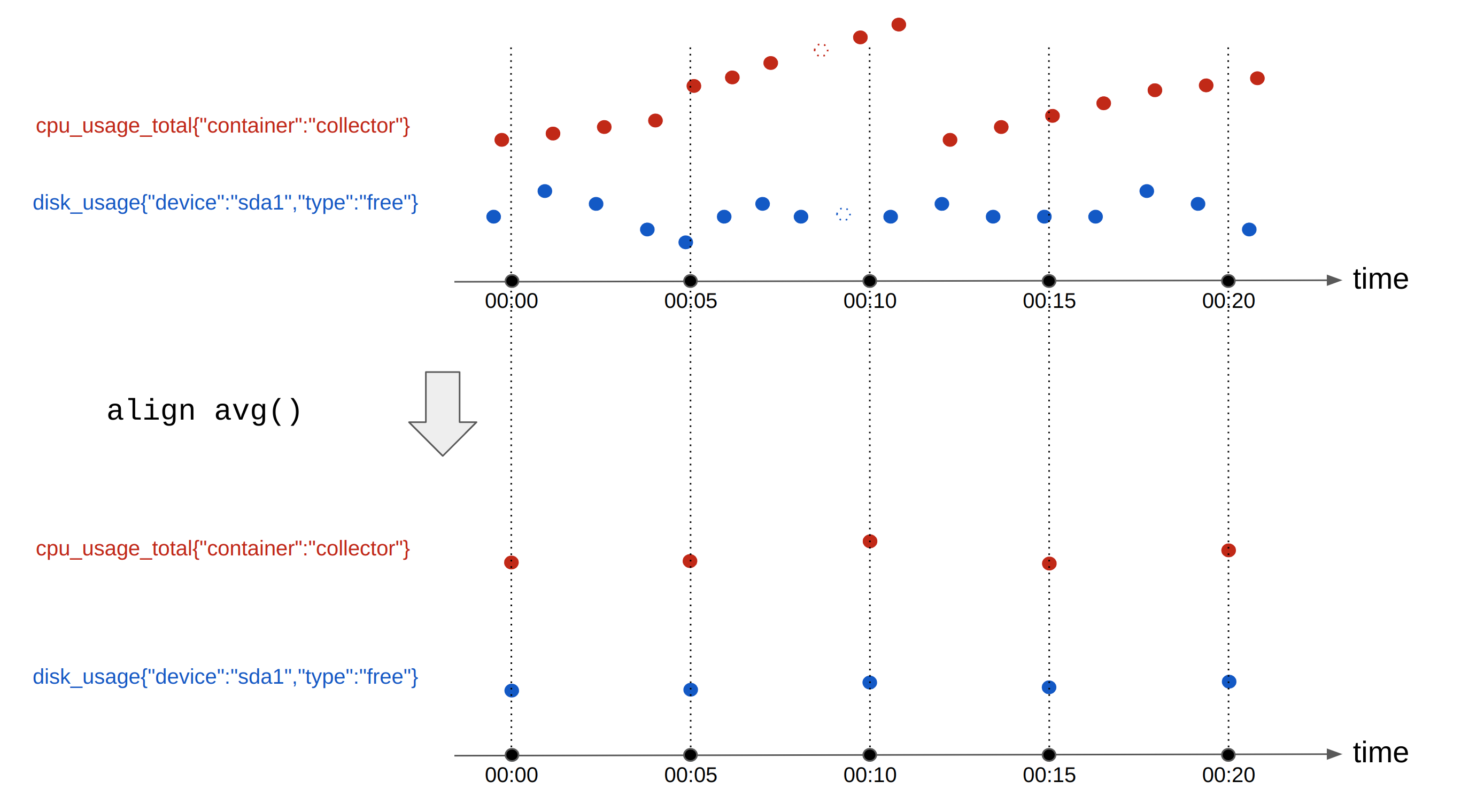
Figure 1 - Metrics aligned with the avg function
A more advanced version of alignment is sliding window alignment, also known as hopping window alignment. It is used for computations like “rolling average”. In this query, for each time-series, we generate one output point every 5 minutes, by computing the average of the input points in the prior 10 minutes. For example:
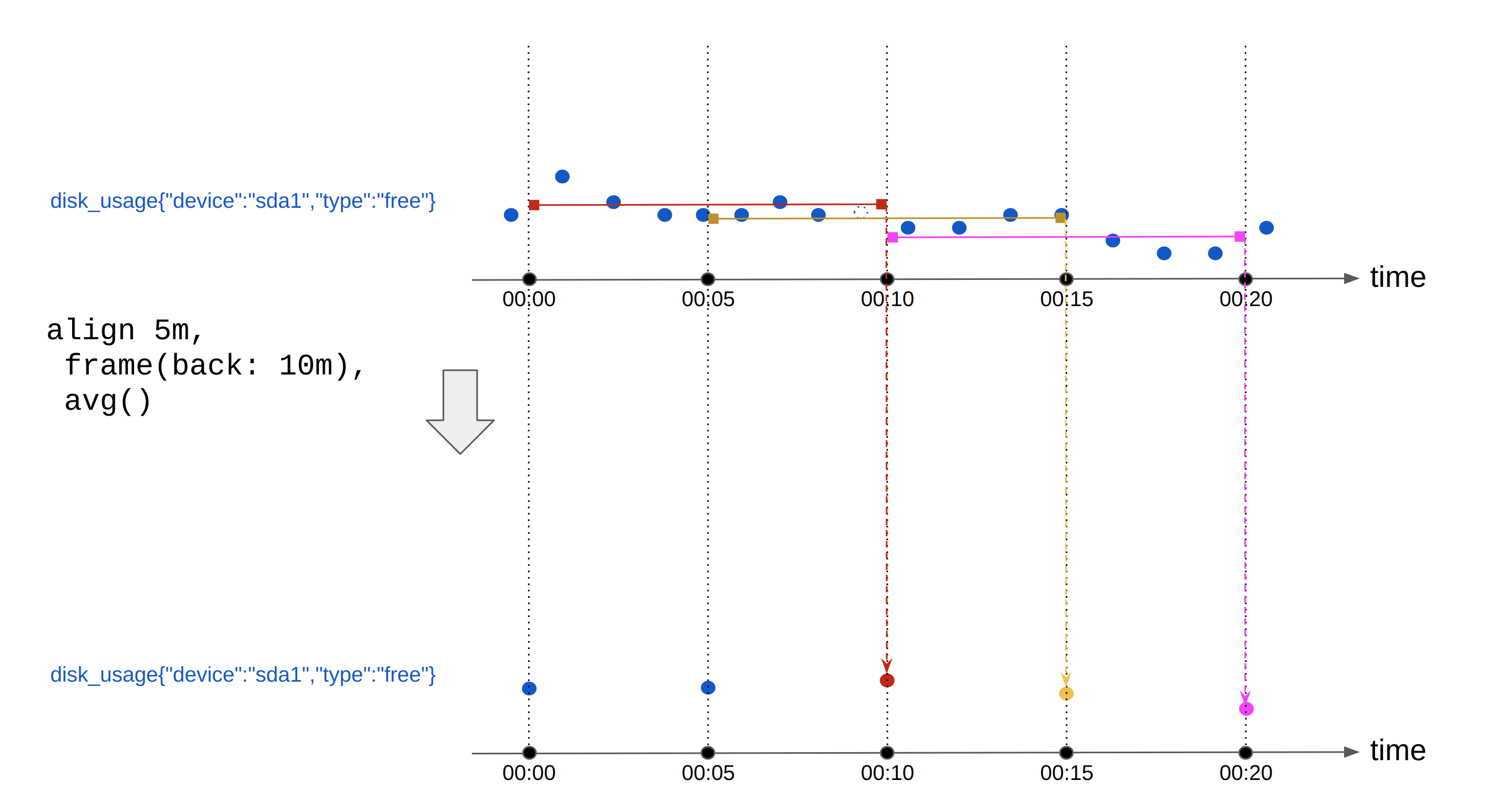
Figure 2 - Metrics aligned with the avg function with a frame
Alignment along other dimensions¶
Time series can be aligned across tags. For instance, consider the same metric “disk-usage” being reported for different device types. We might want to merge those together and get a metric that reports the total disk usage (all device types combined).
A tag-dimension aggregation is an operation that aggregates multiple (already aligned) time series into one. Tag-dimension aggregation takes in regularly aligned time series, and keeps the timestamps unchanged. Aligning across tags also requires an aggregation function to be specified.
Conceptually, tag-dimension aggregation looks like this:
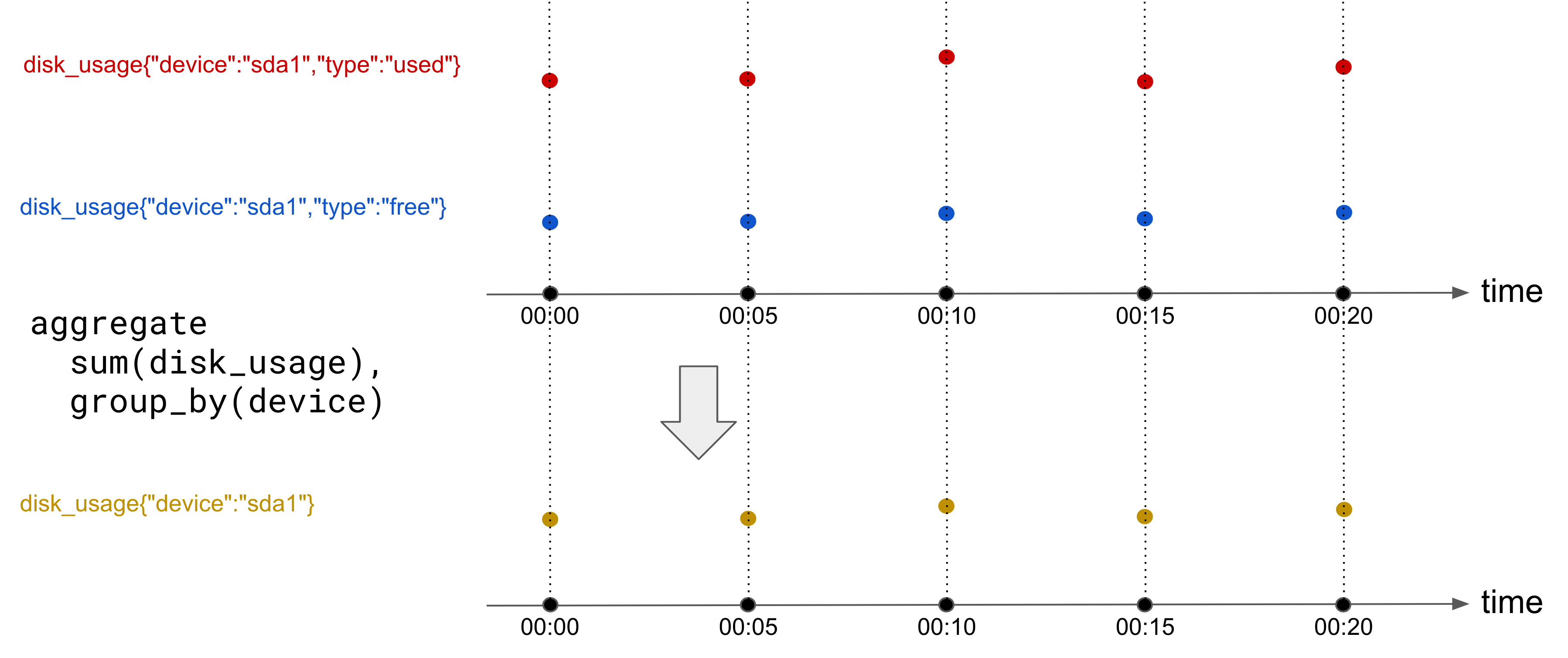
Figure 3 - Metrics aggregated with the sum function
Additional Metrics Metadata¶
In addition to the metric type, the following metadata items can be set:
Measurement type - describes the type of data reported in each data point. Observe supports
float64andtdigestas metric data types.Unit - describes the unit of measurement such as
kborkB/s.Description - detailed information about the metric.
Tags - For a time series, tags better describe and differentiate the measurements. You can use them to identify individual times series during metric computations such as
alignandaggregate.
Figure 4 - Pod memory usage metrics on the Pod dashboard
A Metrics Dataset contains metric data recognized by Observe. Observe optimizes the metric dataset for scalable ingestion and queries, supporting a large number of metrics. A metric dataset has the following properties:
Each row in the dataset table describes one point in a time series.
A metric dataset contains a
stringtype metric value column namedmetric.Contains a
float64metric value column namedvalue.Contains a
valid_fromcolumn with the measurement time for each data point.The
metricinterface OPAL language designates a dataset as a metric dataset.All non-metric names, values, and non-valid_from columns contain metric tags.
A Metrics Dataset is always an Event Dataset and the data either inherited from an upstream Metrics Dataset or created using the OPAL interface verb (see Metric Interface).
Note
Metrics use OPAL in a worksheet to transform the raw data, add metadata, and create relationships between datasets. If you are not familiar with OPAL, please see OPAL — Observe Processing and Analysis Language
A metric dataset contains one metric point per row - a single data point containing a timestamp, name, value, and zero or more tags. For example, the following table contains values for two metrics:
valid_from |
metric |
value |
tags |
|---|---|---|---|
00:00:00 |
disk_used_bytes |
20000000 |
{“device”:”sda1”} |
00:00:00 |
disk_total_bytes |
50000000 |
{“device”:”sda1”} |
00:01:00 |
disk_used_bytes |
10000000 |
{“device”:”sda1”} |
00:01:00 |
disk_total_bytes |
50000000 |
{“device”:”sda1”} |
00:02:00 |
disk_used_bytes |
40000000 |
{“device”:”sda1”} |
00:02:00 |
disk_total_bytes |
50000000 |
{“device”:”sda1”} |
Some systems generate this by default, or you can shape other data into the correct form with OPAL.
Note
Metric values must be either float64 or tdigest. If you need to convert numeric types to float64 see the float64 function. To create tdigest objects, Observe provides tdigest_agg. To combine tdigest states in any dimension, Observe provides tdigest_combine.
input |
function |
output |
|---|---|---|
single numeric values |
|
|
array of numeric or duration values |
|
|
multiple |
|
|
tdigest metrics behave in a slightly different way. Since their value cannot be stored in the same column as other metrics’ values (because the value type is not float64), metrics datasets are allowed to have a second value column to store tdigest metrics’ values and might look like this:
valid_from |
metric |
value |
tdigestValue |
tags |
|---|---|---|---|---|
00:00:00 |
disk_used_bytes |
20000000 |
null |
{“device”:”sda1”} |
00:00:00 |
disk_downtime_nanoseconds |
null |
{“type”:”tdigest”,”state”:[15,1],”version”:1} |
{“device”:”sda1”} |
00:01:00 |
disk_used_bytes |
10000000 |
null |
{“device”:”sda1”} |
00:01:00 |
disk_downtime_nanoseconds |
null |
{“type”:”tdigest”,”state”:[15,1,30,1,2,1],”version”:1} |
{“device”:”sda1”} |
00:02:00 |
disk_used_bytes |
40000000 |
null |
{“device”:”sda1”} |
00:02:00 |
disk_downtime_nanoseconds |
null |
{“type”:”tdigest”,”state”:[],”version”:1} |
{“device”:”sda1”} |
Note that each metric point must have EITHER the value column OR the tdigestValue column populated. The other column should be null. This is because each row in the metric dataset corresponds to one point in one time series. Points that belong to time series “disk_downtime_nanoseconds” (a metric of type tdigest) should only contain tdigest values.
Metric Interface¶
Metrics contained in a generic dataset do not automatically appear in the Metrics Explorer. For that to happen, you must tell Observe that “this dataset contains metrics”. This is done via the “metric” interface. By applying such interface, Observe knows that this dataset contains metrics, and automatically recognizes which metrics are available for visualization!
The interface verb is used to map fields to an interface. In the case of metrics, the required OPAL looks as follows:
interface "metric", metric:metric_column_name, value:value_column_name, tdigestValue:tdigest_column_name
Note
The “tdigestValue” column is optional. It is only required if any of the metrics contained in the dataset are of type tdigest. The interface binding is also optional, and only required if such column is present.
The data you see doesn’t change, but registering or implementing the metric interface establishes the following conditions:
Each row represents one point in a time series
A field named
metric_column_namecontains the metric namesA field named
value_column_namecontains thefloat64metric valuesA field named
tdigest_column_namecontains thetdigestmetric values
If the metric names and values are already in fields called “metric” and “value”, interface discovers them automatically and you can simply use:
interface "metric", tdigestValue:tdigest_column_name
Note
The “tdigestValue” binding, unlike the “metric” and “value” bindings, can never implicit when any of the metrics if of type tdigest.
Now that you understand the types of Metrics collected by Observe and the Observe apps and how to tell Observe about them, try to use the Metrics Explorer feature to easily visualize Metrics Datasets!
Modeling Metadata into Metric Datasets¶
After telling Observe about metric datasets, you may need to customize the individual metrics.
Every metric in Observe can have a type, unit, and description associated with it. Defining a metric using set_metric, lets you set values for all three of these.
Observe uses the metadata of a metric to visualize metrics appropriately. For example, Observe chooses the rate rollup method by default to visualize metrics of type cumulativeCounter, and the Y-axis label displays the unit based on the unit of the chosen metric.
Some metric providers, such as Google Cloud Platform (GCP), AWS, and OTEL, provide metric metadata with every metric point. The metric dataset looks similar to the following table:
Metric |
Value |
Tag |
Type |
Unit |
Description |
Tags |
|---|---|---|---|---|---|---|
Other providers, such as Prometheus, send metadata separately from the metric and do not contain any information about the tags.
A sample observation of a metric point sent by Prometheus with the OBSERVATION_KIND set to prometheus:
{
"__name__": "collector_request_duration_seconds_bucket", // <- metric name
"clusterUid": "23e17bad-48da-427e-9585-ead2231bbcae", //---+
"container": "collector", // |
"endpoint": "/chronicle/eu-west1/dmgprotect", // |
"instance": "172.20.68.149:11000", // |
"job": "integrations/kubernetes/pods", // |<- metric tags
"le": "0.05", // |
"namespace": "prod-eu-1", // |
"node": "ip-172-20-83-237.eu-central-1.compute.internal", // |
"pod": "collector-6dbb6787f9-5bqdn", // |
"status": "202" //---+
}
A sample observation of metric metadata sent by Prometheus with the OBSERVATION_KIND set to prom_md:
{
"help": "HTTP request latency in seconds",
"metric_family_name": "collector_request_duration_seconds", // <- metric name
"type": "HISTOGRAM",
"unit": ""
}
Modeling Metadata¶
Observe provides two ways of modeling metric metadata:
GCP, AWS, and OTEL metrics where the metric includes the metadata
Prometheus where the metrics and metadata are sent separately.
For metrics with included metadata, use the following OPAL:
interface "metric", metric:metric, value:value, metricType:type, metricUnit:unit, metricDescription:description
metricType, metricUnit, and metricDescription are optional parameters for the metric interface. When defined, Observe can find the metric metadata in the columns for these fields.
To model metadata sent separately from metrics, store the metrics and metadata in separate datasets. Datasets containing metrics should implement metric interface and the dataset containing metadata should implement the metric_metadata interface.
Metric |
Type |
Unit |
Description |
|---|---|---|---|
You can define the metric_metadata interface using the following OPAL:
interface "metric_metadata", metric:metric, metricType:type, metricUnit:unit, metricDescription:description