Work with data formats and types
Observe is able to ingest a massive variety of data types and help you work with them directly. The first step of working with that data can often be to change format to make it easier to read. The second step is usually to change type to improve its performance. In this document we will review tools for both tasks.
Parse data formats
It's not uncommon for data to come in large blobs of structured JSON or CSV, which then must be parsed for the specific fields needed.
Given a small blob, such as a CSV of "key","value" or a JSON of {"key":"value"} the OPAL parse_csv or parse_json functions can be ideal. These will render the structured blob as a string.
Alternatively, you may need to extract a specific value. Clicking the column header in a worksheet or Explorer view will give you an Extract from option, such as Extract from JSON. Using this option lets you select one or more values from a structured data set to extract, optionally setting the data types as well. This is an ideal path for extracting specific data blocks, especially because it automatically removes formatting objects like quotes and brackets.
A JSON blob may contain several nested objects, which will be indicated in the Extract from JSON user experience by numbers. For instance, this blob has a top level "tempoOperators" object, flags, and then a series of unnamed objects with their own children.
{
"tempoOperators": [
{
"flags": [
"OperatorFlagsTempoGraphOutput",
"OperatorFlagsTempoStageRoot"
],
"inputOperatorSerialIds": [
1
],
"name": "presentation_simple_order",
"opalSource": null,
"operator": {
"col_order": [
"link_41207219_1",
"accountId",
"link_41207281_2",
"loadBalancerArn",
"link_41207276_3",
"targetGroupArn",
"Monitor",
"SampleValue",
"Valid From",
"Valid To",
"Importance",
"Description",
"Kind",
"MonitorName"
],
"name": "presentation_simple_order"
},
"serialId": 18
}
]
}The JSON extraction tool for this blob shows tempoOperators as a top level, 0 as a level below it, and subsequent levels below that.
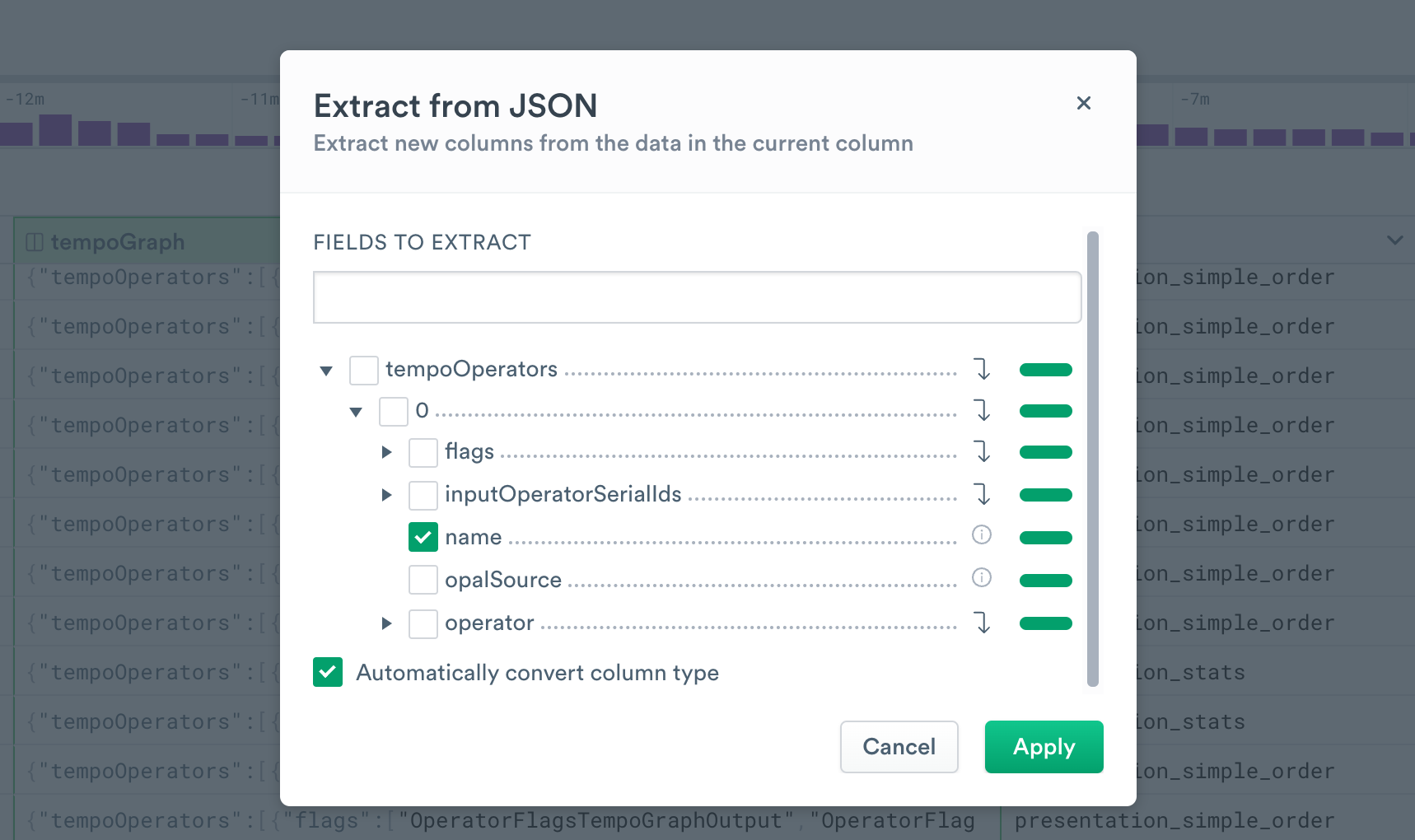
By selecting name we can extract a String column:
| name |
|---|
| presentation_simple_order |
| presentation_rollup |
| presentation_stats |
Manually selecting columns in this way may be tedious given a large blob. Use the following OPAL verbs to assist with automatically extracting columns:
Set data types
Observe will attempt to guess at data types, but it is not always able to succeed. Because performance is greatly improved when the proper type is known, care should be taken when making a Dataset or Monitor to ensure that data types are correct.
If Observe is unable to detect the correct data type, Variant will be used; this is effective for discovery, but will not perform as well as a more accurate type such as String or Int64. See OPAL data types and operators for more detail.
Updated 3 months ago