OPAL syntax
Basic statements, expressions, and queries
OPAL verbs and functions may be combined to perform more complex operations. For example, create a new field with a constructed string value by using make_col and concat_strings() together:
Or calculate a value:
Each line (step) of an OPAL script builds on previous ones, so the city example might look like this:
Numeric literals may be decimal, hex, or octal:
Subqueries
A standard OPAL query is a linear series of steps with one or more dataset inputs. Each action contributes to the final output, but the data coming from those inputs can't be modified in the process.
Subqueries provide more flexibility, as they allow each input to have unique shaping or other pre-processing. Subqueries dramatically reduce the need for intermediate datasets in complex shaping.
The first subquery in a query may filter a dataset one way, the second another, and a third combine those two results with an entirely different dataset and more actions. Together they produce a result, which might be the final result of your OPAL script or passed as input for additional shaping. Subqueries must be defined before you can reference them but otherwise may be located anywhere in an OPAL script.
Subquery containing a single filter
filterThe simplest subquery has one definition block and one result block. OPAL does not require a subquery for a basic filter of course, but here it stands in for whatever OPAL your task may require.
In this example, <- @ indicates we are using the default primary input, weather, without
explicitly specifying it by name. The final <- @test_a {} invokes @test_a to generate the result.
Either of these blocks may have empty bodies, although without filter city="Chicago" the @test_a
subquery would have no effect.
The following example shows a new Worksheet with temperature data for Chicago:
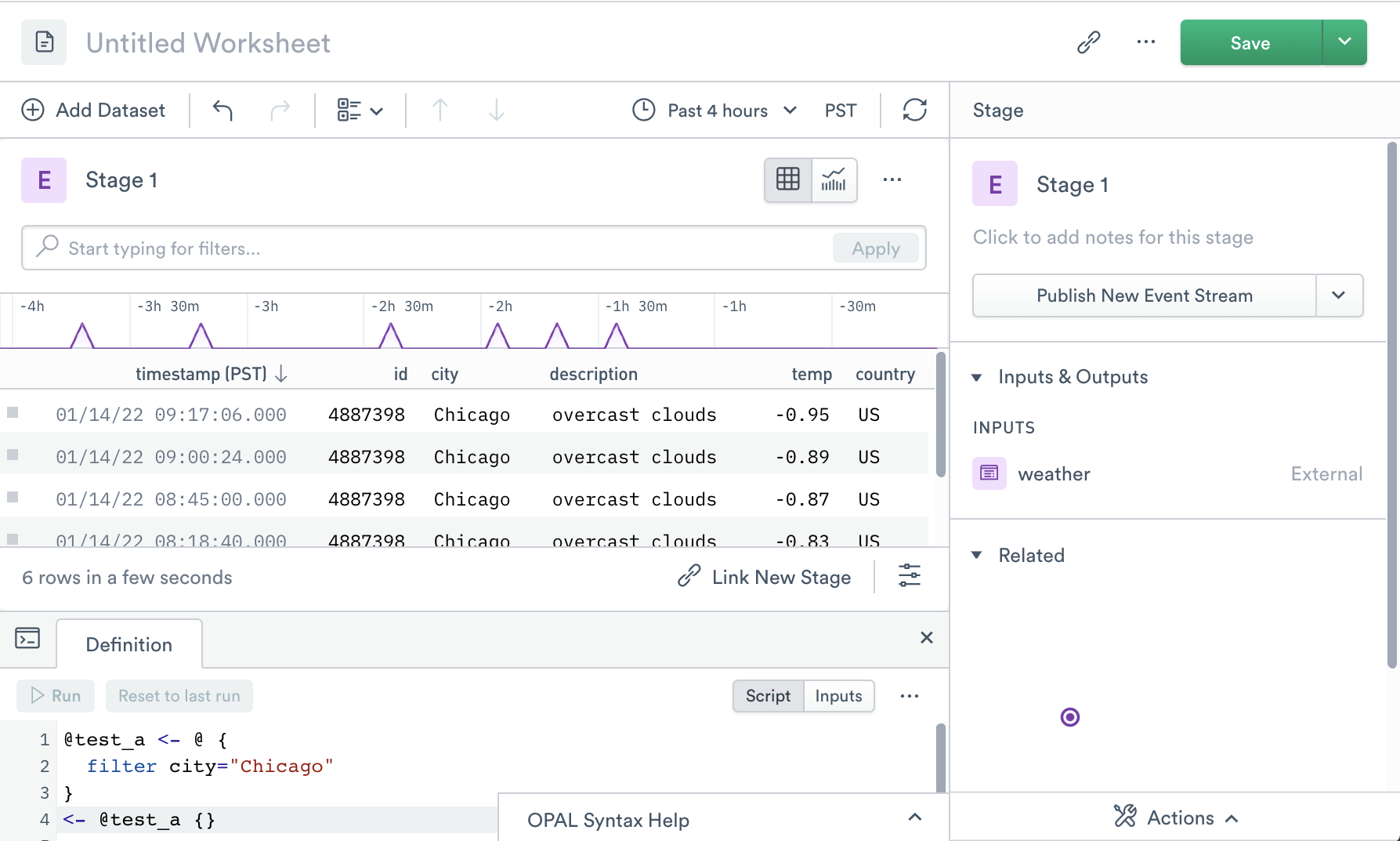
You can also explicitly specify the primary input dataset by name:
For the primary input, you may use either method. Because this is the dataset you originally started with in your Worksheet, Observe can determine what the input dataset should be. Any additional linked datasets, however, must be referenced by name. (See below for examples.)
Spaces and other special characters in dataset names must be HTML escaped (example: %2F for /.) You may find it more convenient to select a dataset from the input menu instead:
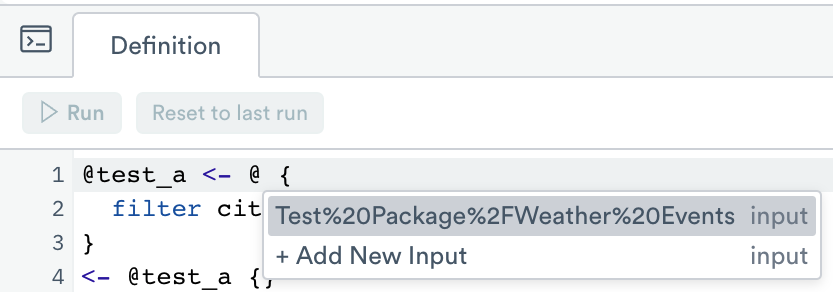
Subquery results may also be used as input for any verb that accepts a dataset:
Queries containing multiple subqueries
Chain multiple subqueries together by using the output of the first as the input to the second:
Two subqueries with different operations on the primary input, combined using union. Note that the final result block is also a subquery, which may contain additional OPAL statements:
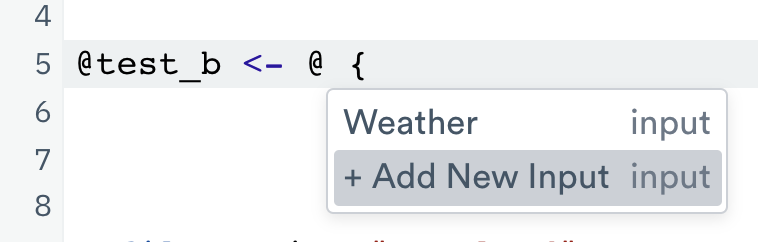
Add other Datasets as inputs
A subquery may use any dataset as an input by linking it. To do this, select + Add New Input from the
Input menu in the OPAL console:
Additional OPAL syntax details
Comments
OPAL allows single line comments beginning with // anywhere whitespace is permitted, except inside a literal string. Ctrl+/ comments or uncomments selected lines in the OPAL console. For multi-line comments, you may also use /* and */ start and end delimiters.
Multi-line statements
Indent to continue a statement on the next line:
Also, regular expressions may be broken into smaller units on multiple lines. Note that each component of a larger regex must be a valid regex, and are whitespace delimited:
Field names
Most field (column) names may contain any character except the following:
- Double quote
" - Period
. - Backslash
\ - Colon
: - Non-printable ASCII characters 0-31 (0x00-0x1F)
Field names may be up to 127 characters long, and Unicode and emoji are allowed. Names containing only alphanumeric (A-Z, a-z, 0-9) or underscore (_) characters may omit the double quotes.
To reference a field with non-alphanumeric characters, use double quotes and prepend @..
NoteRegex extracted columns from
extract_regexare limited to alphanumeric characters (A-Z, a-z, 0-9).
Case-sensitivity
OPAL is case sensitive by default. When you reference or search Observe objects and column names, case is required to match.
There are a few local options for case insensitivity:
- Non-quoted search terms always match case-insensitively (though quoted search terms are case sensitive). See OPAL examples.
- The
match_regexfunction can use regular expression engine flags to be case-insensitive. Seematch_regex. - The
filterverb can use syntax cues to be case-insensitive.
Link fields to resources
Linking fields to Resources is a valuable and useful way to use Observe's features. Linked fields are green in the data grid, and have special context menus and click behavior. Note that referencing these fields in OPAL requires extra syntax. For instance, you may have a link named Session from a session_id column to a Sessions Resource Dataset. Referring to Session in OPAL will produce an error because that column is not actually in this data. Instead, you can use label(^Session) to refer to this column. The OPAL editor will automatically offer this construction when you type Session, so in most cases you will only need to allow it to replace your entry.
Updated 4 months ago