Important concepts
Data acceleration
Observe performs Dataset acceleration using background processes, which periodically and incrementally compute and update the Dataset state. Observe materializes a Dataset state by processing any changes to the input consisting of newly arrived events.
An OPAL pipeline for a Dataset consists of a hierarchic application of OPAL commands from the source observation Datasets to the eventual Dataset. A Dataset is accelerable if the fully expanded definition, or OPAL pipeline, can be accelerable.
Any query can be published into a Dataset, reused, and queried for different query windows. Datasets can also be published on top of other Datasets, forming a pipeline.
NoteYou can accelerate the Dataset for the full queried time range to speed up future queries. However, this operation does consume Observe credits.
Learn more about data acceleration in Queries and on-demand acceleration.
Time dilation
Each query in Observe has a query window, also called the output window of the query. It means “compute all results that fall into this time range” rather than “read the input data that falls into this time range”.
The distinction doesn’t matter for simple queries such as a single filter over an event stream. But it can make a significant difference for more complex queries.
For example, suppose you want to compute the daily sum of system error counts using the following query:
If you want to review a query window for the last four hours, compute the correct result, then sum over a one-day bucket, you must look at more than four hours of data. The timechart verb needs to dilate the input time window of the query to a full day that covers the query window. This means a six-fold or twelve-fold increase in the input data volume compared to the undilated query window.
The following is a list of common OPAL verbs that can incur time dilation:
make_resource- dilation amount determined by the expiry setting of the verb.timechart- dilation amount determined by the bucket sizewindowfunctions - dilation amount determined by the window frameset_valid_from- dilation amount determined by the max_time_diff option.
Time dilation can be a significant cost driver for transforms, which may need to read overlapping input data for successive executions repeatedly.
Acceleration window
Observe calls the time range for which a Dataset has materialized the acceleration window of the Dataset. Queries whose input datasets have been accelerated for the query (dilated) input window are much faster than queries on the raw input data loaded into Observe initially.
Non-accelerable Datasets are always inlined when queried. Examples of Datasets with non-accelerable OPAL include the following:
- Nondeterministic functions, such as
query_start_time() - Verbs used without an explicit frame, such as
ever,never,exists,follow. - Combinations of verbs, functions, and options. For example:
Input data volume
Queries can require different amounts of input data volume. The product of the following factors can determine input data volume:
- Read window size - the size of the time range that the query needs to read.
- Input data rate - the number of rows per second or bytes per second arriving in the input datasets.
- Input columns - which columns in the input datasets need to be read.
Observe uses a column-oriented data layout. Queries only need to read the columns used. This saves time and credits.
For example, if a query reads 10 hours of data from an event dataset with 1,000,000 events per hour, the query reads approximately 10,000,000 rows. The exact quantity of bytes read depends on the set of input columns and the compression factor of these columns, which can range from a few bytes per row to hundreds of kilobytes per row.
Inline queries
Immediately after you define a new dataset, Observe has not yet been able to materialize the state and accelerate it. Observe can temporarily inline the dataset to allow users to use the dataset immediately. Inlining means Observe computes the dataset on the fly by inline-expanding its OPAL definition and prepending that OPAL to the main query.
The same inlining happens when users query historic time ranges that fall outside the dataset’s acceleration window. Such inlining makes the query more complex, potentially reads more input data, and likely to consume additional credits.
Observe never performs more than one level of inlining and does not support nested and recursive inlining. This is to prevent excessive query latency and high costs.
A dataset can be one of the following types:
- A source dataset associated with a Datastream
- An OPAL pipeline defined on top of other Datasets
When Observe queries a non-source Dataset, one of the following actions occurs:
- If the Dataset is accelerated, the query reads the materialized table.
- If it is not, the OPAL definition is inline expanded and prepended to the query.
Query size
Observe attempts to select the ideal data warehouse size to run a given query. Therefore, Observe needs to estimate the size of the query and bases the size of a database query on the following factors:
- Query complexity - the amount of work required per byte of input data
- Amount of input data - the quantity of data in bytes
Besides execution time driven by these two factors, the overall query execution time also depends on these additional parameters:
- Query compilation time - translating OPAL into the optimal execution plan
- Initialization overhead, such as spawning processes or opening network connections
- Returning query results
For queries with very little input data, the time spent on these other factors can exceed the actual execution time spent on processing data.
Query complexity
An Observe query consists of a pipeline of OPAL verbs and functions. Some verbs are more expensive than others because they perform more work per input row. For example, the lookup verb needs to find all matching pairs of rows of two input datasets according to a link established between the two datasets. It needs to find all pairs of rows with matching key fields and overlapping time intervals.
Verbs used with joins such as lookup, join, and follow, as well as aggregations such as timechart, and make_session require more processing time than simple verbs such as filter and make_col.
Transform queries
Observe performs dataset acceleration using background queries called transforms. Transform queries periodically compute and update datasets incrementally, a process known as “materialization.” Dataset acceleration makes subsequent interactive queries fast and cheap. It is essential for low query cost.
Of course, transform queries also consume resources. It is not unusual to see more Observe credits spent on transforms than interactive queries. However, these costs are necessary; otherwise, interactive queries would be much more expensive and prohibitively slow without dataset acceleration. So these transform credits are typically well spent.
The following parameters determine the cost of executing an individual transform query:
- Transform query complexity - the amount of work per byte of data
- Input data volume
- Output data volume
Observe executes transform queries periodically as new data arrives. Four factors determine the frequency and cost of the periodic executions:
- Freshness goal of the output dataset
- Acceleration window - time range receiving acceleration
- Read amplification - frequency of reading the same input data
- Write amplification - frequency of writing the same output data
Each Dataset has a configurable freshness goal. If you set the freshness goal to five minutes, Observe materializes the Dataset every five minutes. In other words, the delay between receiving an observation and seeing the effect on queries and monitors should not exceed five minutes.
The acceleration window contains a range of time that data materializes. A larger window requires more work and storage overhead.
Read and write amplifications result from time dilation. As an extreme example, a transform may run every hour but contain a time dilation of 24 hours. For every hour, this transform needs to read up to 24 hours of input data and over-write up to 24 hours of output data. The read-and-write amplification of this transform is 24x.
To reduce the credit cost impact of read and write amplification, study the OPAL language documentation and choose the appropriate options for verbs that cause time dilation, such as make_resource, timechart, and set_valid_from.
Monitors are materialized datasets as well, with their own freshness goals and acceleration windows. You can review their freshness goal settings in the Acceleration Manager, by filtering to Monitors.
Freshness goal
The freshness goal of a Dataset determines how often Observe runs transform queries to update the Dataset in the background and keep the materialized state up-to-date. This freshness goal is not a strict upper bound, especially when considering other factors such as cost trade offs, freshness decay, and the Acceleration Credit Manager. The freshness goal defines the periodical nature of executing transform tasks, and data may be stale beyond the freshness goal setting while the transform task runs in the background. Furthermore, besides the configured freshness goal of the Dataset, the usage, as well as the freshness goal of downstream Datasets, affects how often transform queries run.
A Dataset with a tighter freshness goal can consume more Observe credits on accelerations than a Dataset with a looser freshness goal. Observe runs the acceleration tasks of Datasets with a tighter freshness goal more often and in smaller batches. This effect may be multiplied by read amplification and write amplification caused by time dilation.
The freshness goal of a Dataset also affects the cost of upstream Dataset acceleration, as Observe runs the upstream transforms more frequently to satisfy the downstream Dataset freshness goal. The minimum of the decayed Dataset freshness goals and any downstream decayed freshness goals dictates the acceleration execution frequency.
Lowering the freshness goal of AWS RDS Logs may transitively lower the freshness goals of all the upstream Datasets in a lineage graph.
Finally, if you enable the Acceleration Credit Manager feature, freshness goals may be loosened to reduce costs. For more information, please consult the Acceleration Credit Manager documentation.
Freshness decay
Freshness decay is a cost-saving feature that gradually loosens the freshness goal to 1 hour whenever a Dataset isn't queried for a while. Freshness decay is instrumental in saving transform credits as the frequency of transform queries is one of the main drivers of their cost (see above).
When a freshness goal has decayed beyond the configured goal and a Dataset is queried, the freshness goal is immediately reset to the original value. If necessary, that triggers a catch-up transform. As a result, the very first query on a decayed Dataset may see data that can be up to one hour stale. But subsequent queries will see new data again as soon as the transform queries have finished.
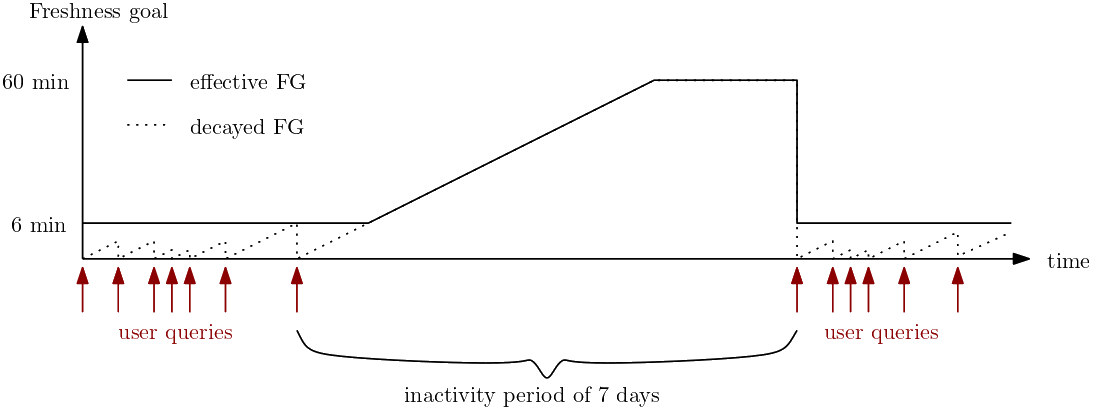
This example shows where the freshness goal (solid line) changes in response to the absence of queries by users. The freshness goal, which is configured to be 6 minutes, decays at a rate of 1 minute per hour without users accessing it. The decay process starts with a freshness goal of 0, which causes the decay effect to take longer on Datasets with looser goals. In this example, the six minute configured freshness goal is tighter than the decayed goal for 6 hours after the last user query. At the 7th hour, the effective freshness goal exceeds the original freshness goal. Once an effective freshness goal of 60 minutes is reached, the goal isn’t loosened anymore, as further cost savings are generally small at this point. As soon as the Dataset is queried again, the freshness goal is tightened back to its setting, and the decay level returns to zero.
Updated 3 months ago